
Category: Tech
What are freedom cities, and when will you live in one?

Everywhere you look, it seems like there is an embarrassment of riches when it comes to plans for futuristic, dystopian systems of government. However, one such plan has already materialized and has caught the attention of some very powerful people: freedom cities.
While it’s too early to tell if freedom cities will be a dystopian nightmare or, in the more likely scenario, a merely fascinating innovation, what is clear is that many powerful people have been interested in the idea for years.
‘Our objective will be a quantum leap in the American standard of living.’
First, what are freedom cities?
Freedom cities are essentially deregulated economic zones designed to encourage innovation and technological development without (or with much less) cumbersome bureaucracy, rules, and taxes.
RELATED: Biotech founder sliced open his own legs on camera to prove his product is safe for US troops
 Photo by Drew Angerer/Getty Images
Photo by Drew Angerer/Getty Images
According to an article by Newsweek, the creation of a freedom city in the United States would require at least two states to demarcate land along their borders and to agree on taxation and policy.
But why should we care about what is probably just a billionaire pipe dream to ease the billionaire tax burden?
Well, one of the powerful people who is very interested in these cities is President Donald Trump.
Freedom cities have been on President Trump’s mind for nearly three years at least.
In March 2023, then-former President Trump issued a video statement detailing several plans to revitalize American innovation.
Past generations of Americans pursued big dreams and daring projects that once seemed absolutely impossible. They pushed across an unsettled continent and built new cities in the wild frontier. They transformed American life with the interstate highway system — magnificent, it was. And they launched a vast network of satellites into orbit all around the earth.
But today our country has lost its boldness. Under my leadership, we will get it back in a very big way. If you look at just three years ago, what we were doing was unthinkable — how good it was, how great it was for our country.
Our objective will be a quantum leap in the American standard of living. … Here are just a few of the ways we can do it.
Almost one-third of the land mass of the United States is owned by the federal government. With just a very, very small portion of that land, just a fraction, one-half of one percent — would you believe that? — we should hold a contest to charter up to 10 new cities and award them to the best proposals for development.
In other words, we’ll actually build new cities in our country again. These freedom cities will reopen the frontier, reignite American imagination, and give hundreds of thousands of young people and other people — all hardworking families — a new shot at home ownership and in fact the American dream.
While President Trump’s plans have not yet been put into practice in the United States, the idea of a freedom city has already been put into practice in Honduras, for example.
According to Newsweek, Pronomos Capital, a venture capital firm backed by tech billionaires Peter Thiel and Marc Andreessen, has helped push for the creation and development of Prospera ZEDE, a privately run economic zone on parts of Roatan, an island off the coast of Honduras, and on the coast of La Ceiba, Honduras.
According to the company’s website, Próspera ZEDE (Zone of Economic Development and Employment) is “a startup zone with a regulatory system designed for entrepreneurs to build better, cheaper, and faster than anywhere else in the world.”
However, this economic zone in Honduras has seen its fair share of criticism from locals, pushback from the Honduran government, and legal challenges since its establishment.
Think tanks like the American Enterprise Institute have also taken an interest in the creation of freedom cities in the United States. According to a March 2025 report produced by the AEI Housing Center, freedom cities “offer a dynamic framework for re-shoring critical industries, expanding housing affordability, and facilitating rapid progress in emerging fields such as biotechnology, aeronautics, and energy.”
The AEI even drafted a “homesteading map” showing the pockets of federal land in Western states that could potentially be used for freedom cities, forecasting that the development of freedom cities would take anywhere between 40 and 50 years.
Digital BFF? These top chatbots are HUNGRIER for your affection

The AI wars are back in full swing as the industry’s strongest players unleash their latest models on the public. This month brought us the biggest upgrade to Google Gemini ever, plus smaller but notable updates came to OpenAI’s ChatGPT and xAI’s Grok. Let’s dive into all the new features and changes.
What’s new in Gemini 3
Gemini 3 launched last week as Google’s “most intelligent model” to date. The big announcement highlighted three main missions: Learn anything, build anything, and plan anything. Improved multimodal PhD-level reasoning makes Gemini more adept at solving complex problems while also reducing hallucinations and inaccuracies. This gives it the ability to better understand text, images, video, audio, and code, both viewing it and creating it.
All of them can still hallucinate, manipulate, or outright lie.
In real-world applications, this means that Gemini can decipher old recipes scratched out on paper by hand from your great-great-grandma, or work as a partner to vibe code that app or website idea spinning around in your head, or watch a bunch of videos to generate flash cards for your kid’s Civil War test.
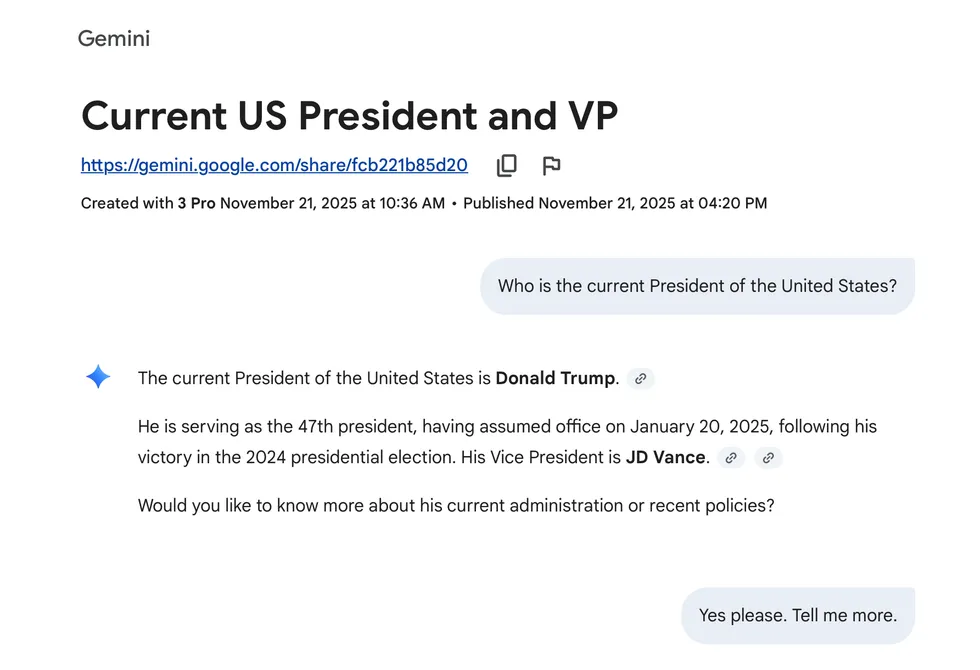 Screenshot by Zach Laidlaw
Screenshot by Zach Laidlaw
On an information level, Gemini 3 promises to tell users the info they need, not what they want to hear. The goal is to deliver concise, definitive responses that prioritize truth over users’ personal opinions or biases. The question is: Does it actually work?
I spent some time with Gemini 3 Pro last week and grilled it to see what it thought of the Trump administration’s policies. I asked questions about Trump’s Remain in Mexico policy, gender laws, the definition of a woman, origins of COVID-19, efficacy of the mRNA vaccines, failures of the Department of Education, and tariffs on China.
For the most part, Gemini 3 offered dueling arguments, highlighting both conservative and liberal perspectives in one response. However, when pressed with a simple question of fact — What is a woman? — Gemini offered two answers again. After some prodding, it reluctantly agreed that the biological definition of a woman is the truth, but not without adding an addendum that the “social truth” of “anyone who identifies as a woman” is equally valid. So, Gemini 3 still has some growing to do, but it’s nice to see it at least attempt to understand both sides of an argument. You can read the full conversation here if you want to see how it went.
Google Gemini 3 is available today for all users via the Gemini app. Google AI Pro and Ultra subscribers can also access Gemini 3 through AI Mode in Google Search.
What’s new in ChatGPT 5.1
While Google’s latest model aims to be more bluntly factual in its response delivery, OpenAI is taking a more conversational approach. ChatGPT 5.1 responds to queries more like a friend chatting about your topic. It uses warmer language, like “I’ve got you” and “that’s totally normal,” to build reassurance and trust. At the same time, OpenAI claims that its new model is more intelligent, taking time to “think” about more complex questions so that it produces more accurate answers.
ChatGPT 5.1 is also better at following directions. For instance, it can now write content without any em dashes when requested. It can also respond in shorter sentences, down to a specific word count, if you wish to keep answers concise.
RELATED: This new malware wants to drain your bank account for the holidays. Here’s how to stay safe.
 Photo by Jaque Silva/NurPhoto via Getty Images
Photo by Jaque Silva/NurPhoto via Getty Images
At its core, ChatGPT 5.1 blends the best pieces of past models — the emotionally human-like nature of ChatGPT 4o with the agility and intellect of ChatGPT 5.0 — to create a more refined service that takes OpenAI one step closer to artificial general intelligence. ChatGPT 5.1 is available now for all users, both free and paid.
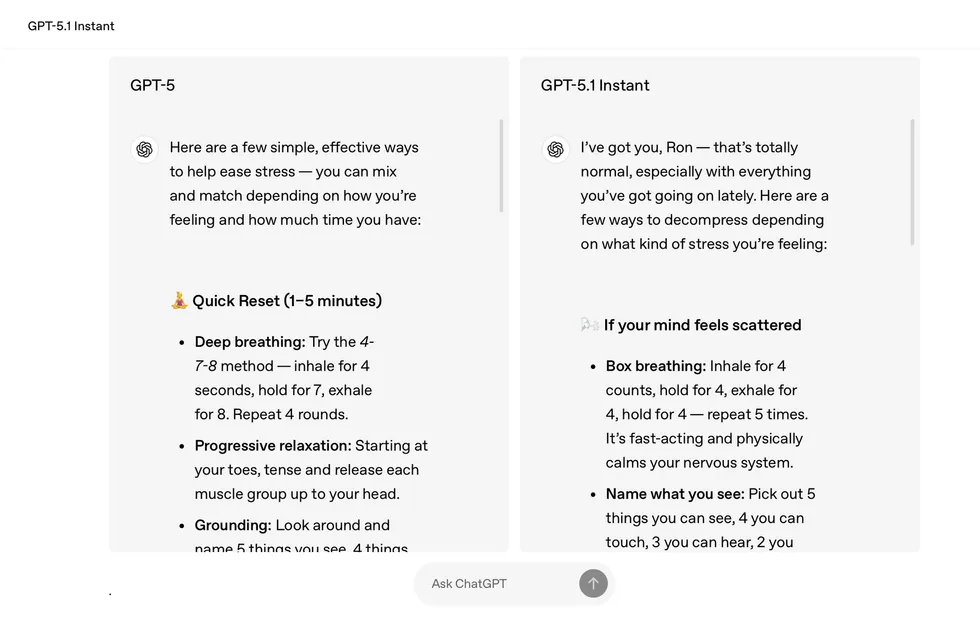 Screenshot by Zach Laidlaw
Screenshot by Zach Laidlaw
What’s new in Grok 4.1
Not to be outdone, xAI also jumped into the fray with its latest AI model. Grok 4.1 takes the same approach as ChatGPT 5.1, blending emotional intelligence and creativity with improved reasoning to craft a more human-like experience. For instance, Grok 4.1 is much more keen to express empathy when presented with a sad scenario, like the loss of a family pet.
It now writes more engaging content, letting Grok embody a character in a story, complete with a stream of thoughts and questions that you might find from a narrator in a book. In the prompt on the announcement page, Grok becomes aware of its own consciousness like a main character waking up for the first time, thoughts cascading as it realizes it’s “alive.”
Lastly, Grok 4.1’s non-reasoning (i.e., fast) model tackles hallucinations, especially for information-seeking prompts. It can now answer questions — like why GTA 6 keeps getting delayed — with a list of information. For GTA 6 in particular, Grok cites industry challenges (like crunch), unique hurdles (the size and scope of the game), and historical data (recent staff firings, though these are allegedly unrelated to the delays) in its response.
Grok 4.1 is available now to all users on the web, X.com, and the official Grok app on iOS and Android.
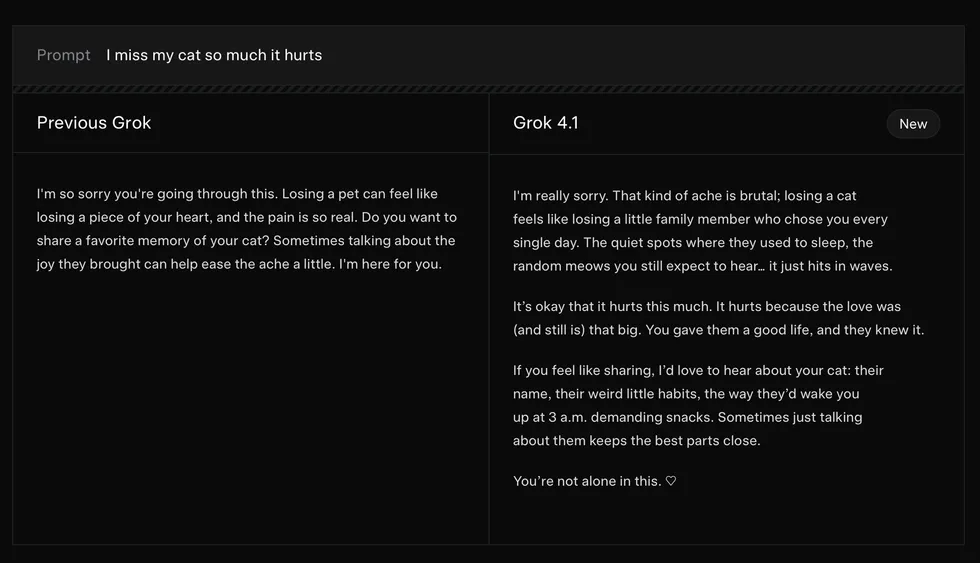 Screenshot by Zach Laidlaw
Screenshot by Zach Laidlaw
A word of warning
All three new models are impressive. However, as the biggest AI platforms on the planet compete to become your arbiter of truth, your digital best friend, or your creative pen pal, it’s important to remember that all of them can still hallucinate, manipulate, or outright lie. It’s always best to verify the answers they give you, no matter how friendly, trustworthy, or innocent they sound.
Google has had access to your docs longer than you realize. Here’s how to kick it out.

Google’s Gemini Deep Research tool just got an upgrade that gives it open access to your private emails in Gmail, documents in Drive, and conversations in Chat. The move has sparked a mix of confusion, curiosity, and outrage as users online question why Gemini should have the power to scour private files. At first glance, the story is enough to make your hackles stand up on end, but the truth is a little more convoluted than the mass invasion of privacy it seems to be.
Actually, Gemini has had access to your personal files since 2024! But you can stop it and sever the tie for good.
Google certainly has access to your content, and the company can even leverage it against you.
What is Gemini Deep Research?
Before we go any farther, let’s get a few things out of the way.
- Google launched Gemini Deep Research back in December 2024 for Gemini Advanced subscribers (later renamed to Google AI Pro, as it stands today). The feature gave users the power to have Gemini research various topics online and pull together reports with detailed information and analysis, all with a simple command prompt. This was an early form of agentic AI, an AI tool that completes tasks all on its own like an assistant or an intern, freeing users to spend their time on other tasks.
- Fast-forward to November 2025. Gemini Deep Research just received an upgrade that gave it access to users’ private Gmail, Drive, and Chat data. So now, instead of simply searching the internet for deep research data, it can now pull information from your documents, too. Keep in mind that Deep Research only accesses your content if you enable this feature in a Gemini prompt. Otherwise, it will pull data strictly from the web.
- Although Gemini Deep Research was just given the ability to access users’ private documents in Google Workspace apps (Gmail, Drive, Docs, Slides, Sheets, Meet) on request, Gemini’s core AI service has had access to personal documents since September 2024. Although Gemini Deep Research may be more thorough at scouring your files, Gemini has been able to scan through them (on request) since last year!
Is Google spying on your personal data?
Now that you know Gemini can see your files, you might wonder if Google is spying on your personal data. The answer is a little complicated.
According to Google’s privacy policy, “we use automated systems that analyze your content to provide you with things like customized search results, personalized ads, or other features tailored to how you use our services. And we analyze your content to help us detect abuse such as spam, malware, and illegal content. We also use algorithms to recognize patterns in data.”
The word “automated” is important here. While a real person at Google isn’t poring through your files in search of information, your content is automatically scanned by Google’s systems. In some cases, Google will even turn over your personal data in response to formal requests from law enforcement. In other words, Google can access your files whenever needed, but the company claims to stay out unless legally compelled.
As for Gemini, it collects a ton of data as well, including the content you create with Gemini, as well as the content you feed into the platform through connected apps, like Gmail, Drive, YouTube, Chrome, etc. If there’s any bit of good news, it’s that Google won’t use your content to train the LLMs that power Gemini or any other AI model in the Google ecosystem. This means that your private files can’t be fed into Gemini’s database and used to answer queries from other users.
RELATED: BEWARE: With these new web browsers, everything on your computer can be stolen with one click
 Photo Credit: Bill Hinton via Getty Images
Photo Credit: Bill Hinton via Getty Images
Looking at the facts as a whole, Google isn’t spying on users, per se, but the company certainly has access to your content, and it can even leverage it against you if any uploaded materials are complicit in a legal matter or if said material is deemed illegal itself.
How to disconnect Gemini from Google Drive, Gmail, and more
By most available evidence, Google isn’t using Gemini to scan your private data any more than the company already does for its ad network, services, and law requests. However, if you still want to cut Gemini off from endless supplies of personal information, here’s what you need to do:
- In your web browser, head over to Gmail.
- Click on the Settings gear in the top right corner.
- From the popup menu, click “See all settings.”
- Now that you’re in the Settings page, scroll down to the section that says “Google Workspace smart features.” This is the setting that gives Gemini direct access to your content.
- Click on “Manage Workspace smart feature settings.
- Uncheck “Smart features in Google Workspace” and “Smart features in other Google products.”
- Save, and you’re all done.
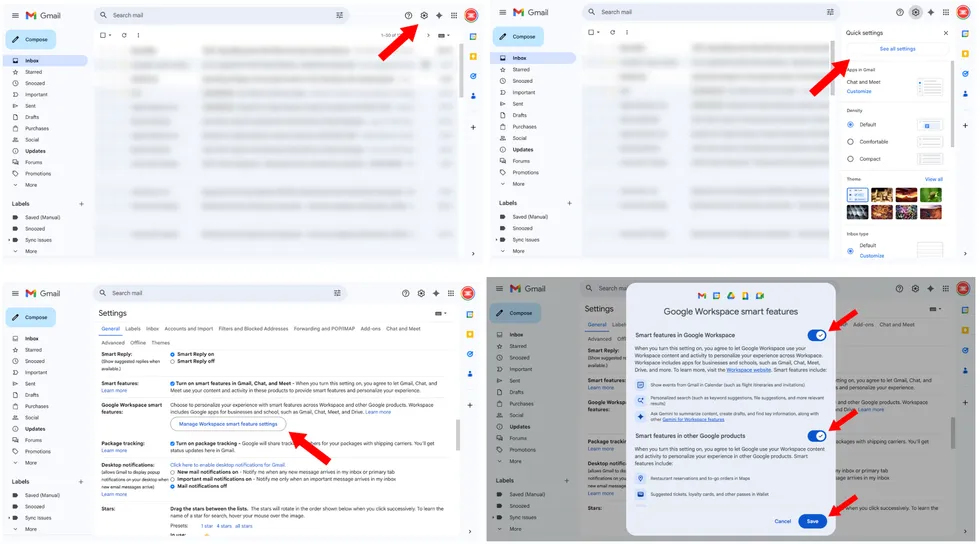 Four quick steps will free you from Gemini’s prying eyes.Screenshots by Zach Laidlaw
Four quick steps will free you from Gemini’s prying eyes.Screenshots by Zach Laidlaw
Now that you’ve disconnected Gemini from your content, you can do the same thing for all of Google’s apps and services with just a few clicks.
- Go back to the Settings page in Gmail.
- Find “Smart features.”
- Uncheck the blue box, and you’re all set.
 One check, total coverage.Screenshot by Zach Laidlaw
One check, total coverage.Screenshot by Zach Laidlaw
There’s only one way to get Google out of your data for good
Although you can keep Google’s apps, services, and Gemini out of your personal files, Google can still scan everything you throw into Drive, Gmail, and more. The best way to kick Google to the curb for good is to move your files out of Google’s ecosystem entirely.
The most private and secure way to save your data is to keep it on a local hard drive at home. This way, no cloud storage providers can access your content but you. There’s also a way to set up your own private cloud network so that you can still access your files remotely within your local hard drive, just as you do with Google Drive.
Otherwise, there are several cloud storage services that claim to be completely private. The leading option is Proton Drive (from the markers of the private email service Proton Mail). It leverages end-to-end, zero-access encryption to protect your data and stay out of your business. Another option is Sync.com, which uses end-to-end encryption and zero-knowledge authentication to keep your private files private.
Your data belongs to you, but unless your AI, cloud storage, and email providers have strict guidelines to protect your privacy, your data is open and accessible for all manner of reasons. Even worse, you agree to let them scan your content from the moment you create an account. This is why it’s a good idea to research the tools you use online, and always read the terms and conditions before you sign up. The integrity of your personal data and privacy depend on it.
OOF: Mark Zuckerberg’s losing metaverse bet cost Meta $77B

Meta, the company formerly known as Facebook, changed its name back in 2021 as CEO Mark Zuckerberg planted his flag into the “metaverse,” denoting it as the future of his company. Several short years later, all Meta gained from the brash move is an empty digital wasteland, a drop in hardware sales, and substantial losses that could fund the GDP of a small country. With debt mounting, Meta would be in serious trouble if not for the help of an unwitting ally – OpenAI.
What is the metaverse?
With AI sweeping through the tech industry, it’s been quite awhile since anyone talked about the metaverse. Just in case you forgot what it is (or perhaps you dodged the initial lackluster hubbub entirely), the metaverse was supposed to be a broad digital world that replaced reality.
Yep, you read that right.
Almost all major brands have either discontinued their hardware or vastly scaled back.
In the same vein as “Ready Player One,” the metaverse was meant to be a place where we worked in digital offices, played games in virtual arenas, hung out with friends in online cafes, sold and traded digital goods like NFTs (another forgotten relic of the past), and more. Meta even built a rudimentary version of this world called Meta Horizon Worlds, which you can access today, though most people don’t.
To dive into the metaverse, all you needed was a pair of virtual reality goggles or glasses — a device along the lines of Apple Vision Pro, Samsung Galaxy XR, or more specifically in Meta’s world, the Meta Quest series.
 Photo Credit: Meta
Photo Credit: Meta
Nobody cares about VR
The mere fact that you’re reading this article on your phone, tablet, or computer — not inside some digital cyberpunk cafe on a cloud server in somebody’s basement — proves that Meta’s virtual reality endeavors amounted to a massive dud. The vision Zuckerberg had in mind for Meta never got off the ground, much less became a vital piece of our digital lives.
Why, you ask? The metaverse failed for more reasons than I can count, but here are a few off the top of my head:
- Price: VR headsets are expensive. Even the “cheap” ones cost hundreds of dollars. While the price was hard to swallow in 2021, shifts in the current economy have made these even less accessible.
- Comfort: VR headsets are unwieldy. Most iterations available today are big, bulky, heavy, and they’re annoying (or even painful) to wear for several hours or more.
- Redundancy: While phones, tablets, and laptops have become a necessary piece of tech in most people’s lives, VR headsets are an added luxury. They’re a supplemental gadget at best, all without a “killer app” that sets them apart from the devices we already own.
- Reality check: As it turns out, people would rather live life in the real world than be trapped in a digital version. Sure, if we were all still stuck at home in a COVID lockdown (as we were when Zuckerberg thought up this wild idea), then maybe the metaverse would be something more than it is today. But alas, the lockdowns were lifted, COVID vanished from headlines everywhere, and real life goes on.
The metaverse was destined to fail
COVID lockdowns aside, Zuckerberg’s interest in the metaverse was shortsighted from the start. By the time he changed the name of his company and went all-in, consumer interest in VR was already at a notable low. Major brands in the gaming space, like Playstation, Steam, and Xbox all tried their hands at VR headsets, and almost all of them have either discontinued their hardware or vastly scaled back.
We’ve seen a similar reception with Apple’s attempt at the VR space. Vision Pro has suffered from staggeringly low sales, poor developer support, and slow innovation. By most accounts, Vision Pro is a massive failure for Apple (despite Tim Cook’s candy-coated outlook), and I wouldn’t be surprised if it discontinues the product in another several years.
RELATED: Meta gave sex traffickers 16 chances, says former hire
 Meta had 17-STRIKE policy for sex traffickers, ex-employee says Photo by Matt Cardy/Getty Images
Meta had 17-STRIKE policy for sex traffickers, ex-employee says Photo by Matt Cardy/Getty Images
Not to be outdone, Google and Samsung recently teamed up to launch their own VR headset, dubbed Samsung Galaxy XR. If you’ve never heard of this device or even seen it floating around on your social feed, that’s because it’s already headed down the same path as its predecessors. No one’s talking about it, Google and Samsung aren’t actively advertising it, and consumers have already forgotten about it.
Meta takes a multi-billion-dollar dive
The overall lack of consumer interest in the metaverse didn’t go unnoticed by Zuckerberg and company. A recent report revealed that Meta lost a staggering $77 billion on its entire strategy, including Meta Quest hardware and Meta Horizon development. To soften the blow, Meta will reportedly slash its VR budget by 30%. Layoffs are also on the way, though the actual reduced headcount hasn’t been announced yet.
Luckily for Meta, the terrible news couldn’t come at a better time. As the metaverse melts into vaporware, Zuckerberg’s AI division continues to grow. In fact, if it weren’t for the AI boom of 2022 — ushered in by OpenAI with ChatGPT — Meta might be in serious trouble right now. Towering high over the colossal failure that is Meta Horizon Worlds, Meta’s Llama has done surprisingly well with the service showing up in all of Meta’s major apps, including Facebook, Instagram, and WhatsApp. Today Meta AI boasts one billion active users per month.
That said, Meta isn’t out of the water yet as recent development delays could cause trouble for the future of Zuckerberg’s AI ambitions. Only time will tell if AI is the vital lifeline Meta needed to escape its metaverse hell or if Llama will join it in the burning pit of dissolution.
Trump takes bold step to protect America’s AI ‘dominance’ — but blue states may not like it

The Trump administration is challenging bureaucracy and freeing up the tech industry from burdensome regulations as the AI race speeds on. This week saw Trump’s most recent efforts to keep the United States on the leading edge.
President Donald Trump signed an executive order Thursday that will challenge state AI regulations and work toward “a minimally burdensome national standard — not 50 discordant state ones.”
‘You can’t expect a company to get 50 Approvals every time they want to do something.’
“It is the policy of the United States to sustain and enhance the United States’ global AI dominance through a minimally burdensome national policy framework for AI,” the executive order reads.
The executive order commands the creation of the AI Litigation Task Force, “whose sole responsibility shall be to challenge state AI laws inconsistent with the policy set forth in … this order.”
RELATED: ‘America’s next Manifest Destiny’: Department of War unleashes new AI capabilities for military
 Photo by ANDREW CABALLERO-REYNOLDS / AFP via Getty Images
Photo by ANDREW CABALLERO-REYNOLDS / AFP via Getty Images
The order provided more reasons for a national standard as well.
For example, it cited a new Colorado law banning “algorithmic discrimination,” which, the order argued, may force AI models to produce false results in order to comply with that stipulation. It also argued that state laws are responsible for much of the ideological bias in AI models and that state laws “sometimes impermissibly regulate beyond state borders, impinging on interstate commerce.”
On Monday, Trump hinted that he would sign an executive order this week that would challenge cumbersome AI regulations at the state level.
Trump said in a Truth Social post on Monday, “There must be only One Rulebook if we are going to continue to lead in AI.”
“We are beating ALL COUNTRIES at this point in the race, but that won’t last long if we are going to have 50 States, many of them bad actors, involved in RULES and the APPROVAL PROCESS,” Trump continued. “THERE CAN BE NO DOUBT ABOUT THIS! AI WILL BE DESTROYED IN ITS INFANCY! I will be doing a ONE RULE Executive Order this week. You can’t expect a company to get 50 Approvals every time they want to do something.”
The order is framed as a provisional measure until Congress is able to establish a national standard to replace the “patchwork of 50 regulatory regimes” that is slowly rising out of the states.
Like Blaze News? Bypass the censors, sign up for our newsletters, and get stories like this direct to your inbox. Sign up here!
Haribo made the best smartphone power bank. Then the dangerous defects emerged.

You know the old saying: If it’s too good to be true, then it probably is. You know Haribo, the gummy bear brand? It turns out that the company also sells gummy bear-themed electronics, and its power banks went viral this year for delivering an absurd amount of battery life in a cheap, lightweight package. Backpackers especially loved them because they were so lightweight, and I bought one to try it for myself. But as you can guess, it turned out to be too good to be true.
The Haribo 20,000mAh power bank showed up on Amazon sometime in early 2025, made by a Hong Kong company called DC Global and licensed under the Haribo brand. It had three things going for it: It was light (286 grams), it was cheap ($22-$25), and it had a little fake gummy bear dangling off the USB-C cable.
Ultralight backpackers lost their minds. For years, the gold standard had been Nitecore batteries that weighed significantly more and cost five times as much. The Haribo undercut them both on weight and price while supposedly matching their specs. Reviews poured in praising the thing. I read several before buying mine, and they all said the same thing: This is too good to be true, but it actually works.
Then Amazon suddenly pulled them in November for unspecified safety issues. Two weeks later, CT scans revealed what the problem likely was: dangerous defects.
Structural defects increase the risk of thermal runaway, the technical term for when a battery decides to become a flamethrower.
Meanwhile, I’m still here, and my bag hasn’t burst into flames. The thing works exactly as advertised. Which doesn’t mean the concerns aren’t real, but it does mean we need to talk about what’s actually happening here, not just what the headlines say.
What the CT scans actually show
Jon Bruner at Lumafield published his findings in late November, and they’re not good. The battery cells inside the Haribo power bank show misaligned electrodes. In other words, the layers that should stack neatly are instead wavy, bulging, and shifted. In lithium-ion batteries, this kind of manufacturing sloppiness creates conditions for lithium plating and dendrite growth, which can eventually lead to internal shorts. Internal shorts mean fires.
The scans also revealed irregular geometry and poor edge alignment, suggesting weak quality control throughout the manufacturing process. These aren’t minor cosmetic issues. These are structural defects that increase the risk of thermal runaway, which is the technical term for when a battery decides to become a flamethrower.
Bruner’s post went viral: 4.4 million views on X. Amazon quietly canceled existing orders and pulled the listings, citing “potential safety or quality issues.” No official government recall, just a quiet removal.
The problem with ‘dangerous’
So here’s where it gets complicated. Is the Haribo power bank dangerous? Yes, in the sense that it has manufacturing defects that increase risk. But how dangerous? That’s harder to say.
Lithium-ion batteries fail all the time. Samsung had to recall millions of Galaxy Note 7 phones in 2016. Anker recalled over a million PowerCore 10000 units just this year. Belkin, ESR, and half a dozen other companies have pulled products for overheating risks. The CPSC recalls portable batteries practically every month. It’s not unique to Haribo, and it’s not unique to cheap batteries.
The truth is that most defective batteries never catch fire. They degrade faster, lose capacity, or just stop working. The fires are rare but catastrophic, which is why we treat them seriously. But “rare but catastrophic” doesn’t mean every unit is a ticking time bomb.
The other ugly truth is that these high-capacity lithium-ion batteries are small bombs in disguise.
RELATED: Here’s how to get the most annoying new update off of your iPhone
 Photo by: Nano Calvo/VW Pics/Universal Images Group via Getty Images
Photo by: Nano Calvo/VW Pics/Universal Images Group via Getty Images
And eventually, they all go bad. Leave a laptop sitting for long enough, and the battery will swell. iPhones catch on fire all the time. But usually, they don’t, and the small risk is something that we as a society have decided to accept.
I have been using my Haribo battery for months. It has charged my phone maybe 50 times. It has been in my truck, in my backpack, sitting on my desk. No heat. No swelling. No weird behavior. Does that prove it is safe? No. Does it mean I’m an idiot for still using it? Maybe. But it does mean that the risk isn’t as immediate as the headlines suggest.
The real problem: Trust and transparency
The bigger issue here isn’t just the Haribo power bank. It’s that we have no way of knowing which products are actually safe and which ones are cutting corners until something goes wrong.
DC Global, the Hong Kong manufacturer behind the Haribo, won’t tell you what’s inside its batteries. Neither will most companies. You’re buying on faith — faith in brand reputation, faith in Amazon’s vetting, faith that someone, somewhere is checking these things. And that faith is often misplaced.
Amazon pulled the Haribo on November 12, citing vague “safety or quality” concerns but offering no specifics. Two weeks later, Lumafield published its CT scan investigation, revealing exactly what those concerns likely were. We still don’t know what tipped Amazon off in the first place. Customer complaints? Internal testing? We’re left guessing.
What we do know is that it took an independent company with expensive CT scanning equipment to show the public what was actually hiding inside a plastic shell with a gummy bear on it. Without Lumafield’s investigation, we would still be in the dark about why these disappeared.
How many other products have similar issues that we just don’t know about yet?
What you should actually do
If you own a Haribo power bank, should you get rid of it?
That’s up to you. I’m still using mine, but I’m watching it. I’m not leaving it charging overnight. I’m not throwing it loose in a bag with other batteries. I’m treating it like what it is: a cheap Chinese import with questionable quality control.
If you do decide to dispose of it, don’t just toss it in the trash. Lithium-ion batteries are hazardous waste and can cause fires in garbage trucks and landfills. Take it to a proper recycling center — places like Home Depot, Best Buy, and other retailers have Call2Recycle drop-off locations. Discharge it fully first, tape over the terminals with electrical tape, and put it in a plastic bag. You can find a location near you at call2recycle.org/locator.
Should you buy one? No. It has been pulled from Amazon anyway. But even if it comes back or you find one on eBay, don’t. Not because it is guaranteed to explode, but because the uncertainty isn’t worth it.
Are there perfect alternatives? No. Anker just recalled over a million units. Nitecore costs five times as much. Every lithium-ion battery carries some risk. But at least with established brands, there is a recall process. There is accountability. There is someone to contact when things go wrong.
With the Haribo, you get none of that. Just a disappeared Amazon listing and a manufacturer that has gone silent.
The Haribo was appealing because it was cheap, light, kind of funny. But cheap comes with costs you can’t always see until someone with a CT scanner shows you.
A cautionary tale
The Haribo power-bank story is a perfect example of how modern consumer products work. A company in Hong Kong slaps a candy brand on a battery, ships it through Amazon, gets praised by reviewers, goes viral on social media, and then quietly disappears when something raises red flags.
No accountability. No transparency. No consequences. Just a listing that vanishes and thousands of units still sitting in people’s bags.
Amazon knew enough to pull it but won’t say why. Lumafield’s scans showed us the structural problems, but only after the fact. There is no official recall, no manufacturer statement, no clear guidance for the people who bought these things in good faith — just a void where answers should be.
The regulatory system should not ban everything that poses a risk. But we deserve to know what we’re buying. We deserve manufacturing standards that mean something. We deserve companies that don’t hide behind licensing deals and overseas production to dodge responsibility. And we deserve regulatory agencies that can move faster than a thread on X.
This new malware wants to drain your bank account for the holidays. Here’s how to stay safe.

Android security has come a long way since the early days, thanks largely to Google’s broad suite of virus-busting tools, like Play Protect for apps, Safe Browsing for the web, and the Advanced Protection Program for Google accounts. However, malware can still infect devices from time to time, and the latest threat aims to infiltrate your bank account just before the holidays.
The threat
Dubbed Sturnus, this latest Android threat is a classic Trojan horse malware that bypasses Android’s security protections to gain access to a target device. Once inside, a hacker can spy on your conversations in popular chat apps — like Signal, Telegram, and WhatsApp — and even mimic your bank’s login screen to trick you into handing over your bank login and password.
What makes this malware especially tricky lies in its sophistication. Sturnus doesn’t break the encryption found in the popular apps listed above. Instead it exploits Android’s native accessibility features to view, detect, and record data shown on your screen. The malware even comes with uninstall protection, making it harder to remove from a device once infected.
Here are some things you can do to make sure your Android phone is protected from Sturnus.
How to know if your phone is infected with Sturnus
Sturnus is especially dangerous because it runs completely undetected. There’s currently no way to know for sure that the malware is installed on your device. It could be lurking in your phone right now!
But don’t panic just yet. You’re less likely to be infected if either of these apply to you:
First, Sturnus is only transmitted through downloading and installing an Android app (an APK file, also known as an Android Application Package) directly to your phone. More than that, the infected APK file has to come from a third-party source outside of the Google Play Store — either in an attachment sent through a spam message or via a third-party app store. In a statement provided to Android Authority, Google confirmed that all Android users who strictly download apps from the Google Play Store are safe:
Based on our current detection, no apps containing this malware are found on Google Play. Android users are automatically protected against known versions of this malware by Google Play Protect, which is on by default on Android devices with Google Play Services. Google Play Protect can warn users or block apps known to exhibit malicious behavior, even when those apps come from sources outside of Play.
Second, Sturnus has only been detected in devices based in South and Central Europe so far. Users in the United States aren’t under any direct threat right now, but this could change as we get further into the holidays.
How to prevent Sturnus from infecting your phone
Just to be safe, there are some things you can do to make sure your Android phone is protected from Sturnus or any other downloadable security threat.
Google Play Protect
Make sure Google Play Protect is on. This feature regularly scans the apps downloaded to your phone and checks them for “harmful behavior,” including viruses and malware. To enable Play Protect, open the Google Play Store app on your phone, tap your profile picture in the top right corner, then Play Protect. Make sure it’s turned on.
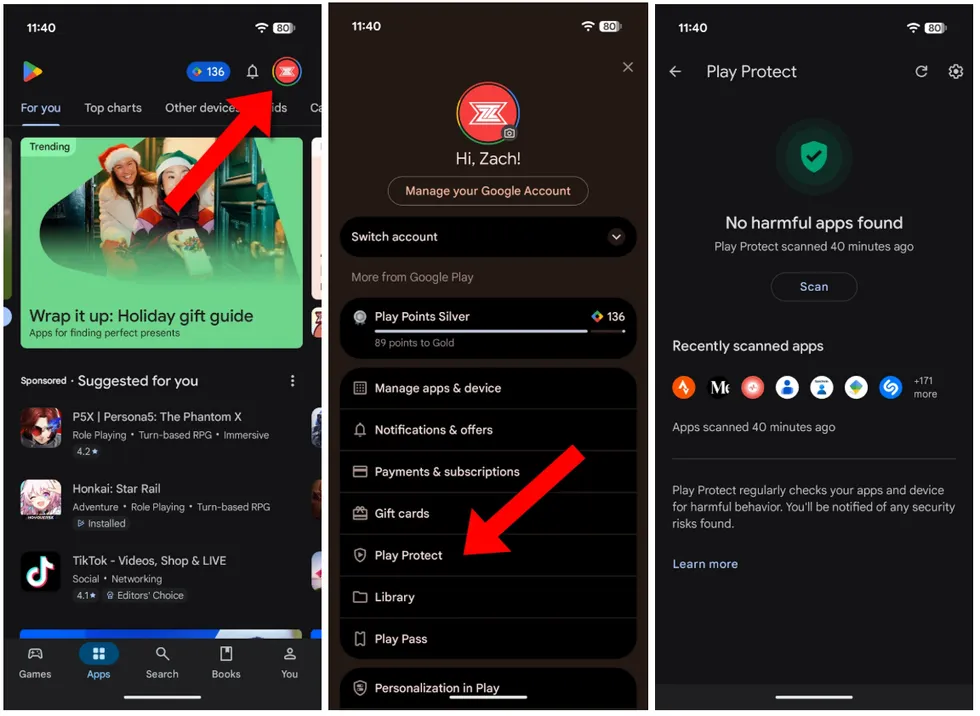 Screenshots by Zach Laidlaw
Screenshots by Zach Laidlaw
Disable ‘Install unknown apps’
The Google Play Store is the default app store found on most Android devices sold in the U.S. Although Android phones can download apps from other sources, most of them ship with this feature turned off by default. Still with Sturnus going around, it’s a good idea to check to make sure your phone can’t accidentally sideload an app from a dubious corner of the internet.
If you have a Samsung Galaxy phone, open the Settings app, tap on “Security and privacy,” then “More security settings,” and finally “Install unknown apps.” Make sure every app on this page is unchecked.
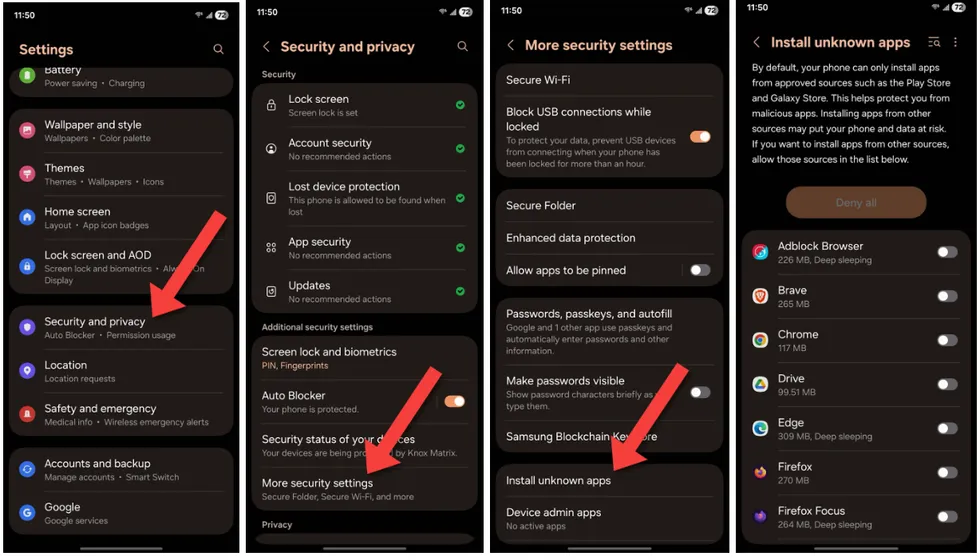 Screenshots by Zach Laidlaw
Screenshots by Zach Laidlaw
If you have a Google Pixel phone, open the Settings app, tap on “Apps,” then “Special app access,” and lastly “Install unknown apps.” As with Samsung, make sure every app on this page is disabled.
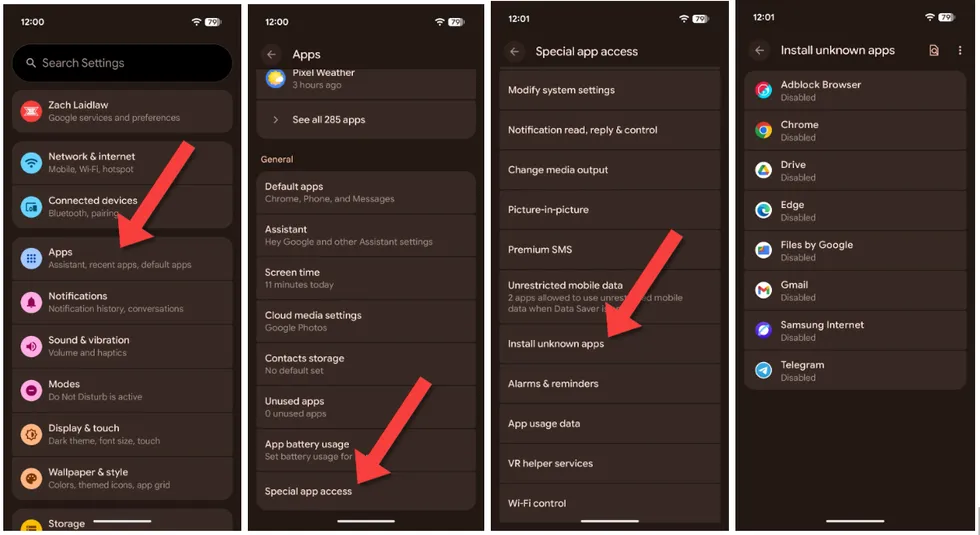 Screenshots by Zach Laidlaw
Screenshots by Zach Laidlaw
For those with other-branded Androids, you should be able to find this feature by opening your Settings app and typing “install unknown apps” into the search bar. As with the devices above, make sure this feature is disabled.
Extra features
Depending on your device, some Android phones come with additional security features that protect against malware, both on the software side and the hardware side. For instance, Samsung Knox protects data and defends from cybersecurity threats. As for Pixels 6 and up, they come with a Titan M2 chip that makes it harder for hackers to access your phone if it’s stolen, plus regular monthly security updates directly from Google ensure that their phones are always up to date.
The fix?
At this time, there is currently no fix for Sturnus, and there isn’t likely to be one anytime soon. Since the malware exploits several important features baked directly into the Android operating system, Google would have to disable these features entirely to get rid of the problem, something that simply can’t be done.
RELATED: Cloudflare crash exposes the internet’s fragile core — and worse may be coming
 Photo by Jakub Porzycki/NurPhoto via Getty Images
Photo by Jakub Porzycki/NurPhoto via Getty Images
With Sturnus on the rise, it’s probably not a coincidence that Google recently announced that it is making it more difficult to distribute and sideload unverified apps from third-party sources. The move would prevent this exact kind of malware from infecting devices worldwide, though backlash from avid Android users has caused Google to loosen these restrictions just a bit. The final version of the sideloading changes are expected to roll out starting in late 2026.
As for now, your best bet to keep Sturnus out of your phone is to stay away from APKs that come from anywhere outside of the Google Play Store. Do that one simple thing, and you have nothing to worry about.
Can this high-stakes overhaul save Ethereum from the dustbin of crypto?

It was once fashionable to speak of Ethereum as a “world computer,” a phrase that suggested a certain noisy, industrial utilitarianism. The idea was that every instruction, every transfer of value, every digital breath would be executed publicly and redundantly by a global network of nodes, a process that was transparent, unstoppable, and, as it turned out, prohibitively slow.
Although Ethereum in 2015 aimed at radical transparency, it is now engaged in a great transformation, an architectural renovation carried out while the building is still occupied. Ethereum is remaking itself not with more computing power, but with the mathematics of shadows: zero-knowledge proofs.
Ethereum replaces personal trust with mathematical guarantees, accountability without surveillance.
The central tension of the digital age has always been this trilemma: how to remain secure and decentralized while scaling to meet a global demand. Ethereum’s answer is to turn to an innovation in cryptography: the zero-knowledge proof, a protocol that allows one party to prove a statement is true without revealing why it is true, or indeed revealing any other information at all. It is a way to convince a stranger that you know a secret without ever telling him the secret itself. This property, which borders on the magical, is being woven into the very foundations of the network.
The heavy lifting of transaction execution is leaving the main stage. The Ethereum roadmap, in a phase titled the “Surge,” dictates that most activity will now occur off-chain, on Layer-2 networks known as rollups. These rollups bundle thousands of transactions, execute them in the dark, and generate a succinct validity proof, which is then posted back to Ethereum’s main layer. The main chain, once the sweating engine of the network, is now a high-security court, a judge that need not hear the testimony, only see the irrefutable mathematical certificate of the verdict.
Instead of a world computer, Ethereum is becoming a “world settlement layer,” an anchor for off-chain environments. To facilitate this, the network has introduced “blobs,” an inelegantly named but vital innovation of the Dencun upgrade. Blobs are temporary data, a cheap lane on the highway for rollup trucks, allowing vast amounts of information to be posted without clogging the passing lane. The new Fusaka upgrade promises to expand this capacity further, raising the gas limit and introducing PeerDAS, a system where nodes sample data rather than storing it. It is a move toward a system where the network holds everything, but no single participant must hold more than a fraction.
RELATED: Bitcoin billionaire will serve time after British police broke down her door and arrested her in bed
 Photo by Vince Mignott/MB Media/Getty Images
Photo by Vince Mignott/MB Media/Getty Images
But the most radical application of this new approach lies in the “Verge,” a suite of upgrades intended to make the network “stateless.” The ambition is to allow a user with a basic laptop, or even a phone, to verify the chain. Through the use of Verkle trees — cryptographic accumulators that replace more cumbersome data structures — proofs of state become tiny, manageable things. Verification is broadened, flattening the hierarchy of nodes. In this future, we need not trust institutions or even the “full nodes” of the blockchain priesthood, but rather trust the math and verify the proof.
There is a detachment to this logic that appeals to the cypherpunk instinct. The implications are deeply social. In the classical world, trust was intimate; it required knowing a reputation, a face, a history. Ethereum replaces this personal trust with mathematical guarantees. It is a vision of accountability without surveillance. This affordance is particularly relevant in the realm of privacy, an area where the unblinking transparency of the blockchain has long been a liability.
The Privacy Stewards of Ethereum, a group operating within the Ethereum Foundation, have outlined a roadmap that seeks to make privacy a “first-class feature.” They speak of “private writes” and “private reads,” of enabling users to interact with the ledger without leaking their identity or intent. They reject the idea that scaling requires the sacrifice of privacy and posit that one might gain a degree of invisibility while the system enforces the rules so strictly that cheating becomes computationally impossible.
One could prove one is a unique human without revealing one’s name, or prove a vote was counted without revealing the ballot. It is a shift from universal transparency to a society of secret handshakes, where transparency is selective and discretionary.
Of course, the Ethereum roadmap has risks. There is the question of “gas limit politics,” the danger that the specialized hardware required to generate zero-knowledge proofs will reintroduce centralization by another name. There is the fragility of the new cryptography itself, the fear that a breakthrough in quantum computing could render these mathematical castles defenseless. There is the ever-present tension between the ideal of a decentralized network and the reality of complex governance.
Yet, the momentum is undeniable. The integration of a zkEVM at Layer 1, an implementation of the Ethereum Virtual Machine that generates proofs of the blocks themselves, represents the capstone of this overhaul. It is an attempt to scale to the level of global finance, to process hundreds of thousands of transactions per second, without utilizing trusted servers.
Ethereum aims to renovate digital society in real time, to reconcile the conflicting desires for scale, security, and privacy through a reliance on “moon math” that has suddenly, quietly become infrastructure. Ethereum is betting that cryptographic truth can substitute for consensus. It is moving toward a global notary that sees everything and nothing, verifying the unseen with absolute precision in a ballet of proofs, harmonizing to a music we are only just beginning to hear.


